0Prim 1somehs 2hsgrad 3somecol 4colgrad
0 0.50102529 0.62285381 0.76896442 0.82792701 0.91397195
1 0.49897471 0.37714619 0.23103558 0.17207299 0.08602805研究设计与数据分析原则
政务大数据应用与分析 (80700673)
胡悦
清华大学
概述
研究设计原则
- 科学研究
数据收集原则
- 抽样与权重
- 变量测量
数据分析原则
- 统计基础
- 重复性截面数据分析
- 软件与数据资源
问题
AI时代为什么还要学统计和计量?
研究设计原则
社会科学
Is soft science a real science?
信念
程序
方法
研究程序
问题导向
- 问题提出
- 理论假设
- 数据方法
- 实证检验
数据导向
- 观察数据
- 分析方法
- 规律总结
- 理论提升
问题来源

研究步骤
想法 → 判断 → 证据
呈现形式
描述
- 无偏(正确😄)
- 高效(准确😅)

机制
Why & how
关于机制的几个争议
定义
- 因果本质
- 决定论 vs. 概率论
- 因果路经
- 多重因果
- “互为因果”
测量
Y ~ X vs.
Y ~ A → B → C → D → E → … → X
观测

Bonus: 因果推断工具
- 方差分析
- 非参数检验
- Lasso
- SEM
- 倾向值匹配
反事实分析 (counterfactual analysis)
- 实验
- 观察数据
- Difference in difference
- Regression discontinuity
- Counterfactual estimators (FEct, IFEct, MC)/ synthetic control
- Regression
小结
研究设计原则
- 科学:信仰 + 程序 + 方法
- 步骤:问题导向 or 数据导向
- 形式:描述 and/or 机制
数据收集原则
大数据迷思
- 什么样的数据是好数据?
- “每日上亿条”
- “全网数据”
- “《人民日报》所有文章”
- 收集什么样的数据
- 新的?
- 多的?
- 没censored的?
大数据收集原则
大数据不是全数据
全数据不一定是好数据
抽样
从一大堆到一小撮 ⇒ 代表性
- 简单随机抽样
- SHA算法和MD5
- 计算机随机数
问题: 为什么要随机
- 复杂抽样
- 配额(quota)
- 分组(clustering)
- 分层(stratification)
矫正
- 有限总体校正(finite population corrections, FPC)
- 不相等权重(unequal weights)
复杂抽样


常见设计
S + W + (FPC)
- Strata
- 减少点估计的标准误;
- 不同层抽样权重不等;
- PSU/SSU/TSU
- Weight
- 样本入选概率的倒数;
- 各抽样阶段权重的乘积;
- 抽样权重在总体层面是等概率的,但在个体层面是非等概率;影响点估计的计算
后果
- Stratification → 层间方差不齐;
- Clustering → 群组间方差不齐,群组内不独立;
- Weighting → 某些特征分布与总体不一致.
复杂抽样是不得已而为之
如果“假装看不见”会怎么样
Behavioral Risk Factor Surveillance System (BRFSS) County data by US Centers of Disease Control and Prevention (CDC)
Unweighted
Weighed
0Prim 1somehs 2hsgrad 3somecol 4colgrad
0 0.54784913 0.69288237 0.80457219 0.86034095 0.92834751
1 0.45215087 0.30711763 0.19542781 0.13965905 0.07165249分析差异
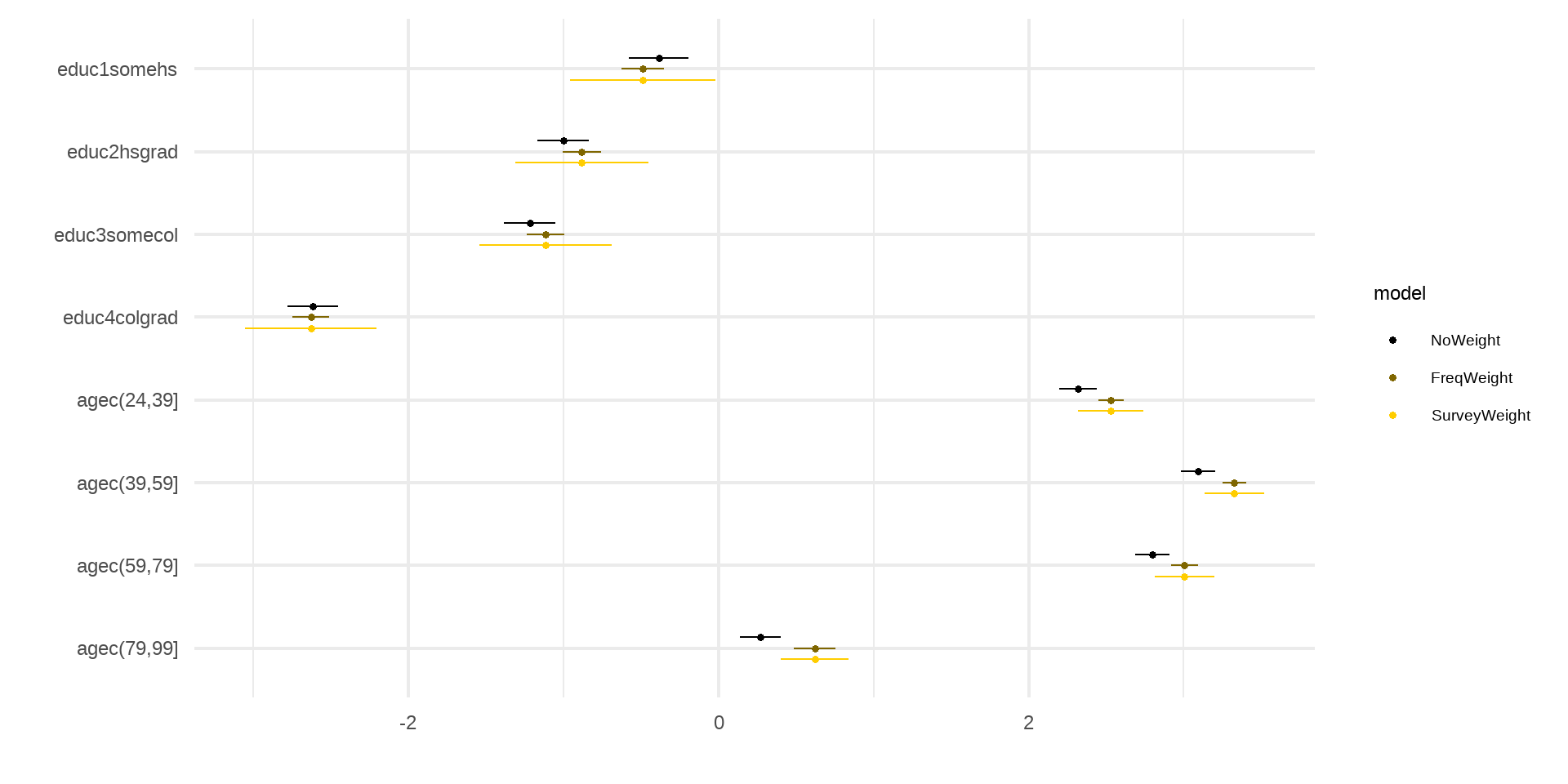
小结
数据收集原则
- 代表性 → 抽样
- 简单抽样
- 复杂抽样
- 复杂抽样步骤
- 分配额/层/群
- 权重
- 复杂抽样分析:考虑权重
数据分析原则
学科概念
统计学 vs. 计量经济学
Statistics vs. Econometrics
统计学
分类I
- 理论统计学
- 应用统计学
分类II
- 描述统计
- 推断统计

基础概念辨析
数据
- 总体 vs. 样本
- 抽样误差
分析
- 参数 vs. 系数
- 期望
- 不确定性
材料
- 数据
- 变量、变量值、缺失值
测量
- 定类
- 定序
- 定距
- 定比
问题
一个研究者想了解全市居民上个月的平均通讯支出是多少元,为此在全市人口中随机抽取了1800个居民进行了访问,得到了这些居民上个月的平均通讯支出为300元。
请指出以上叙述中,总体、样本、参数、系数各是什么?
问题
调查发现,人们对市政府工作的满意度,在不同年龄、教育水平、收入、职业以及不同户口人群中都有显著的差异。
问题:上述这段描述中提到了几个变量,分别是什么类型的数据?
(变量)测量类型
类型
- 直接(Raw data)
- 整合(Aggregated data)
- 潜在 (Latent measurement)
记录
- 变量(variables)
- 观测层级 (unit of analysis)
- 观测对象(observations)
结构化数据
Tidy version

数据 → 很多数据
面板数据
好
(成本高,样本局限大🙄)
重复抽样数据
周期性调查
每次随机
时序性信息
e.g., WVS, DCPO, Global barometers, CGSS, CFPS, CEPS, CLDS, CUGS, CHFS, GSS, CESS…
呈现社会、政治、经济现象的变化趋势
探索特定人群(Cohort)社会行为与态度的变迁模式
适用于识别自然实验的效应
数据分析
描述性分析
- 解读数据结构
- 显示、理解变化趋势
比较分析
- 跨层级分析
- 跨时间分析
- 跨区域分析
总体分析
- 对核心变量一般表现的衡量
- 与比较分析不分先后
数据分析工具
- 分析软件:STATA, SAS, SPSS, EXCEL
- 编程语言:R, Python, Matlab, JAVA, C++
举例:爱国主义教育基地
描述分析

总体比较分析

总结
研究设计原则
- 科学:信仰 + 程序 + 方法
- 步骤:问题导向 or 数据导向
- 形式:描述 and/or 机制
数据收集原则
- 代表性 → 抽样
- 简单抽样
- 复杂抽样
- 复杂抽样步骤
- 分配额/层/群
- 权重
- 复杂抽样分析:考虑权重
分析原则
- 变量
- 数据
- 分析工具